Az titokzatos ukrán kapcsolat
Nyelvek lexikai távolsága
Nem mindig a mi hibánk, ha valamit nem értünk. Tudományos eredményeket lehet ábrázolni akkor is, ha nincsenek mögöttük tudományos kutatások – vagy éppen nem tudjuk, milyenek. Pedig az eredmény gyakran egyszerűen attól függ, hogyan számolunk. Bár vannak eredmények, amelyek elvben semmilyen számolással nem jöhetnek ki...
Az emberiséget legalább a 18. század vége óta lázba hozzák a nyelvek leszármazási viszonyai és mindenféle rokoni kapcsolatai. Akkoriban gyakran használták a természeti metaforákat, maga a rokonság szó is ebből származik. A nyelvészetben sokat finomodott már a nyelvrokonság fogalma, de a hétköznapi gondolkodásba az ilyesmi nem egyhamar szűrődik át. És mivel a nyelvek közötti kapcsolat legbanálisabb, legfeltűnőbb fajtája a legtartalmasabb szótövek átvétele, ez vonja magára a legtöbb ember figyelmét, és a naiv szemlélő úgy gondolja, hogy a nyelvrokonságnak is ez a legfőbb vetülete.
Szavak, szavak, szavak
(Forrás: Wikimedia Commons / H. Andrew Schwartz et al. / CC BY 3.0)
Ugyanakkor közhelyszerűen közismertek az olyan faramuci helyzetek, mint az angol nyelvé, amelyben állítólag a szókészlet háromnegyede normann-francia eredetű. Ugyanakkor ha a szótöveknek nem a számát, hanem az előfordulását tekintjük, akkor kb. 80% a germán eredetű szótövek száma (mert a leggyakoribb szavak tartoznak a szókészlet germán rétegébe). Mindenesetre mindettől függetlenül az angol egyértelműen germán nyelv, és a francia eredetű szótövek magas számának az égvilágon semmilyen hatását nem lehet kimutatni az angolul beszélők közösségének semmilyen tulajdonságán. Hasonló furcsaságot sok nyelvben találunk, például az újperzsában (a farsziban) az arab szótövek száma igen magas (ennek ellenére indoiráni nyelv, nem pedig sémi), vagy a magyarban is rengeteg az indoeurópai és török nyelvekből származó jövevényszó, mégis egyértelműen uráli (közelebbről finnugor) nyelv.
Mindezt azért bocsátottam előre, hogy rámutassak: a szótövek között a kölcsönzöttek aránya sok kultúrtörténeti érdekességről tanúskodik, de a nyelvek rokonságáról nem. Megjegyzem, a fenti példákban éppen kultúrtörténeti szempontból sincs semmi meglepő, hiszen mind az angol, mind a perzsa és a magyar szókészlet közismert történelmi eseményeknek megfelelően alakult. És persze ha a toldalékok eredetét figyelmen kívül hagyjuk, akkor még kisebb az összefüggés a szókészlet közös eredete és a nyelvrokonság között, mert a toldalékok között ritkább az idegen eredetű.
Az oldal az ajánló után folytatódik...
„B” nevű olvasónk figyelmét éppen egy olyan közlemény keltette fel, amelyik a nyelvek közötti szókészletbeli (tehát lexikális) egyezésekről szól:
Egy ismerősöm linkelte be ezt a rövid cikket egy levelezésünk folyamán mondva, hogy érdekes, én azonban nem egészen értettem. Mármint, mintha a cikk nem a grafikonhoz kapcsolódna, (keveri a lexikai és grammatikai kapcsolatokat?). Pontos a diagram ezzel a címmel?
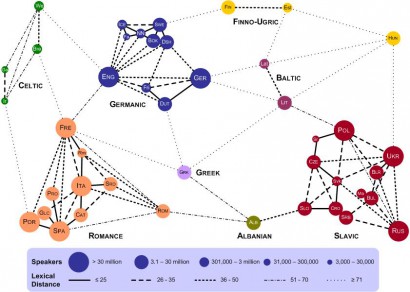
Lexikális távolságok Európa nyelvei között
(Forrás: elms.wordpress.com)
Nos, olvasónknak csak azt válaszolhatom, hogy az idézett igen rövid írás igenis a grafikonhoz kapcsolódik, és igenis a szókészletbeli, lexikai kapcsolatokról szól (egyébként megemlíti azt is, amit feljebb az angol nyelv szókészletéről írtam). Az írás csak egyetlen hibát tartalmaz: Kosztyantin Tiscsenko műve,
A nyelvészet metaelmélete (Metateoriia movoznavstva) tudtommal nem oroszul, hanem ukránul jelent meg, és nem 1999-ben, hanem 2000-ben, ami
a szerzővel készült angol nyelvű interjúból is kiderül. Én nem olvastam ezt a könyvet, de úgy tűnik, hogy ő nagy jelentőséget tulajdonít annak, amit a nyelvek közötti „lexikai távolságnak” nevez, vagyis annak, hogy két nyelvnek milyen arányban azonos eredetűek az egymásnak megfelelő szótövei.
Azt sem tudom, hogy pontosan hogyan számolt Tiscsenko. Hogy néhány nehézségre rámutassak, a magyar nyelv példáját fogom használni. Vajon végigtanulmányozta-e Tiscsenko A magyar nyelv történeti-etimológiai szótárát (a TESz.-t), és így állapította-e meg a szótövek eredetét? Ha igen, akkor például hogyan kezelte a szláv eredetű szavakat? A fent említett cikkben a magyar és az ukrán nyelv között van a legnagyobb ábrázolt „lexikai távolságot” jelző vonal, ami azt jelentené, hogy a többi feltüntetett szláv nyelvtől a távolsága még ennél is sokkal nagyobb. Viszont a TESz. (de ugyanígy a többi forrás is) bizonyosan viszonylag kevés szláv jövevényszó esetén teszi le a voksot amellett, hogy egy bizonyos szláv nyelv lett volna az átadó nyelv, és még e viszonylag kevés eset között is igen ritka az ukrán nyelvnek mint átadónak az említése. Ha pedig nem a közvetlen átadó nyelv számít Tiscsenko módszerében, hanem a szótövek közös eredete, akkor még inkább indokolt lenne, hogy szinte minden szláv nyelvtől egyforma távolságban legyen a magyar.

Híd a tiszán Záhony és Csap (Csop) között. Erős kapocs?
(Forrás: Wikimedia Commons / VargaA / GNU-FDL 1.2)
Hasonlóképpen rejtélyes, hogy minek lehet köszönhető, hogy a magyar nyelvet az észttel hasonló vonal köti össze, míg a finn nyelvvel semmilyen. Nem tudom, mi indokolhatja azt, hogy a magyar és az észt között jelentősen kisebb lenne a „lexikai távolság”, mint a magyar és a finn között.
Hozzászólások (13):
Követem a cikkhozzászólásokat (RSS)
13
Janika
2014. március 6. 14:28
@Fejes László (nyest.hu): Persze, egyetgértünk. Szándékosan írtam egy olyan extrém példát, amit talán egyetlen "romantikus nyelvész" sem fogad el. Egy olyan bonyolult dolgot, mint a távolság fogalma a nyelvek között, szerintem nem lehet egzaktul meghatározni. Inkább csak érzések, szubjektív megállpítások lehetnek. Még a genetikusoknak is könnyebb dolguk van, mivel ha egy génállomány egy adott időpontban szétvált és külön fajok jöttek létre, később már nem tudnak visszakeveredni. (a házimacska pl már nem keveredik a pöffeteggombával) A nyelvi állományra vizsont hatásal lehetnek olyan nyelvek is, amik lehet hogy már több ezer éve különváltak. Pl egy ősi indián kifejezés simán átkerülhet a magyarba.
12
Skubidor
2014. február 28. 01:59
@Janika: gratula, fején találtad a szöget !
11
Skubidor
2014. február 28. 01:50
Mindenki megőrült ? Teljesen nyilvánvaló, hogy a magyarnak az "olasz-latin" nyelvi irányban van a legtöbb átfedése. A legtöbb azonos szótő, hasonló szó, és azonos betűcsoport az azonos értelmű szavaknál. És nem beszélve az azonos betűvel kezdődő szavakról. Az ukrán az egyik legtávolabbi nyelv, a magyartól. Szerintem a cikk írója egyálltalán nem ismeri a magyar nyelvet. Az etruszk-olasz-magyar nyelvi összefüggésekről Mario Alinei könyvet írt.
10
mederi
2014. február 25. 18:55
Ami számomra szembeötlő a cikkben szereplő lexikális nyelvtávolsági ábrán, hogy:
-az összekötő vonalak erőssége alapján, a finn/ észt és kelta nyelvekhez hasonlóan, nagyon "halványan kötődönk" a többi nyelvhez...
-a finn, szláv, és balti nyelvekhez az ábra szerint "hasonló mértékben" kapcsolódunk, gondolom a vonalhalványság azt jelenti.
-Az ábrázolás módja olyan tekintetben is elnagyolt (bár lehet, hogy csak "kezdeti", és ha lesz több feldolgozott adat még bővül és finomodik), hogy csak "egymáson keresztül" jutunk el egyik "csomópontról" a másikra, vagyis "sík" és nem "térszerű" a háló..
-Másik hiányosság számomra, hogy nem láthatók tájékoztató jelleggel a perem feltételek (pl. a felhasznált kifejezések nyelvenkénti darabszáma, a szavak, kifejezések anyanyelvi használatának gyakorisága, stb..)
9
HF-C
2014. február 24. 19:45
aha, ezek szerint nem en voltam, hanem ez a rendszer rakja bele a space-t, amikor a komment egy hosszabb sora a doboz szelehez er. Tehat a linkben a "(2013" reszt követö zarojel elötti szoközt ki kell venni a böngeszöben es akkor megy. sorry. többet mar nem irok, igerem... :)
8
HF-C
2014. február 24. 19:41
7
HF-C
2014. február 24. 19:39
6
HF-C
2014. február 24. 17:35
Szerintem barmit is csinalt a szerzö, az biztos hogy nem a TESz-böl es megfelelöiböl indult ki, hanem olyasmit csinalhatott mint pl. ezek itt: iopscience.iop.org/0295-5075/81/6/68005/pdf/0295-5075_81_6_68005.pdf
az eljaras lenyege:
- vesznek egy cognate-listat (nem tudom hogy van sajnos magyarul, tehat azonos jelentesü szavak csoportjat N különbözö nyelven)
- atirjak mindet fonetikai jelekkel, mondjuk IPA-val, vagy valami egyertelmü hangjelölö modszerrel (lehetöleg olyannal, h egyetlen szamitogepes karakter egyertelmüen egy hangot jelöl)
- kiszamoljak a Levenshtein-tavolsagokat, vagy valami hasonlot (ld. en.wikipedia.org/wiki/Levenshtein_distance ), azaz hogy hany behelyettesitö-betoldo-törlö lepessel lehet az A nyelvü szoalakbol a B nyelvö szoalakot letrehozni
- ezt minden nyelv-parra es sok cognate-ra megcsinaljak
- es igy az atlagos Levenshtein-tavolsagokbol allhat elö ez a rejtelyes "lexical distance" nevü mennyiseg
Persze ezt csak betippeltem, mert ez a gyakran hasznalt eljaras. Itt van egy masik szep pelda jobban kifejtve, egy disszertacio: dissertations.ub.rug.nl/faculties/arts/2004/w.j.heeringa/
Szoval, en csak azt tudom elkepzelni, hogy egy ilyen jellegü modszer adhatja ezt a furcsa eredmenyt, ami magyarazhatja a "titokzatos ukran kapcsolatot", vagy hogy miert epp az esztekkel tzalalt egyezest a rendszer.
5
El Vaquero
2014. február 24. 17:17
Még valami: ahogy az ábrás cikk hozzászólásainál többen szóvá teszik: egy csomó nyelv nem is szerepel rajta.
4
El Vaquero
2014. február 24. 17:15
Ááá, ez teljesen fal, egy csomó minden egy rakat mással nincs összekötve, vagy rossz helyen van összekötve. Főleg az az ukrán-magyar összekötés elég durva, de a görög-holland összekötés sem piskóta. Pedig az ötlet nem rossz, hogy így ábrázoljunk nyelvrokonságot, de a kivitelezés nagyon elnagyolt.
3
Fejes László (nyest.hu)
2014. február 24. 16:42
@Janika: Azért a nyelvek magyar elnevezése irreleváns szempont az egyes nyelvek szempontjából, ahogyan az állatok magyar neve sem mond semmit a fajról. Bizonyos lexikális mérések tényszerűen mondanak valamit (pl. rokon nyelvek esetében a közös eredetű szókincs mérete mond valamit a rokon nyelvek közötti távolságról), és a jövevényszavak száma/gyakorisága is lehet tényező (pl. a magyart érte erősebb szláv hatás, vagy a románt). A probléma ott van, amikor túl összetett méréseket kívánnak végezni, ráadásul pontos mérési elvek nélkül, és a számszerű adatokat is ad hoc interpretálják.
2
Janika
2014. február 24. 16:18
Ez a nyelv összehasonlítás elég népszerű téme. Gyakorlatilag bármilyen szempontot ki lehet találni, amivel összehasonlíthatjuk a nyelveket. Az egyik összehasonlításban ilyen nyelvek vann közel egymáshoz, egy másikban meg olyanok. Mí csak azt sem mondhatjuk egyérterlműen, hogy ez tudományos öszehasonlítás az meg nem. A nyelvészek a nyelvrokonságot a nyelvtörténet alapján határozzák meg. Van akik a hangzás és megint mások gyakran használt szavak, szótövek hasonlóságára alapoznak. A fenti cikk lexikai távolsággal próbált mérni. Egy extrém példa, én találtam ki:
Hülyeség indul:
Mérjük a nyelvek közti távolságot azzal, hogy a nyelvek megnevezése magyarul, a magyar ABC-ben milyen messze van egymástól.
pl az angol és az amerikai ez alapján közeli nyelvek, míg a bolgár és a török távoliak. Jó kis eredmények születhetnek: pl az olasz, a portugál és a spanyol közeli nyelvek, a német és a norvég is. A francia közelebb áll az etióphoz, mint a kínaihoz, a kínai-japán meg szinte ugyanolyan, stb.
Hülyeség vége.
Egzakt a vizsgálat? Igen! Tudományos? igen, hiszen világosak a feltételek, a mérés megismételhető, a világ távoli pontján dolgozó kutató ez alapján ugynerre az eredményre jutna, stb.
Ez olyan mint amikor a fajok közti kapcsolatot régen a külső tulajdonságaik alapján próbálták meghatározni. Aztán jött a gentika és kiderült, hogy közeli fajok nézhetenek ki egészen különbözően, hasonlóan kinéző egyedek viszont lehetnek genetikallag nagyon távol egymástól. Valami ilyesmi lehet a nyelvekkel is.
1
Sultanus Constantinus
2014. február 24. 08:45
Nagyjából szerintem is stimmel a grafikon (az újlatin nyelveknél legalábbis elég jól ábrázolja).
Azt én sem értem, hogy a magyar miért pont az ukránnal van összekötve, akkor már inkább valamelyik délszláv nyelvhez kellene mennie a vonalnak.
Lehet, hogy az adatokat az Ethnologue-ból vették.