

-
Sándorné Szatmári: @mederi: 11 Kiegészítem a korábbi, mederi néven írt megjegyzésemet.. Ami a cikkben is kife...2025. 06. 05, 13:16 Falánk igék
-
nasspolya: @ganajtúrós bukta: www.reddit.com/r/linguisticshumor/s/BuJhBlK4t82025. 06. 01, 01:06 „Mert nincs rá szó, nincsen rá...
-
Sándorné Szatmári: @szigetva: Korábban számos valóban értelmetlen bejegyzések és viták fóruma is volt helyenk...2025. 05. 18, 16:36 „Mert nincs rá szó, nincsen rá...
-
szigetva: @Sándorné Szatmári: A viták az új cikkek hiánya és a vitaképes kommentelők elmaradása miat...2025. 05. 14, 10:56 „Mert nincs rá szó, nincsen rá...
-
Sándorné Szatmári: @Sándorné Szatmári: 43 Remélem, hogy a 43. hozzászólást már nem törlitek (.. ezt is mentet...2025. 05. 14, 08:39 „Mert nincs rá szó, nincsen rá...
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!


Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság

A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


Az ember esendő, figyelmetlen – éppen ezért jobb, ha számítógép ellenőrzi a feltételezéseit.
Új indoeurópai nyelvtörténeti szótár jelent meg a világhálón. Sajátossága, hogy nem csak azt mutatja meg, mely indoeurópai tövekből milyen szavak fejlődtek, hanem azt is hogy hogyan. Ráadásul nagyon következetesen. Ezt a következetességet számítógép garantálja.
Az oldal az ajánló után folytatódik...
A Jouna Pyysalo doktori értekezésére épülő projekt lényege pontosan ez a következetesség. A nyelvtörténészek úgy képzelik, hogy volt egy alapnyelvi alak, és a nyelvek története során ezeken különböző változások mentek végbe – ezek a változások azonban az adott feltételek mellett minden egyes szóban végbementek. Ha azonban több száz szóról és több száz szabályról van szó, akkor nehéz ellenőrizni, hogy valóban történhetett-e minden úgy, ahogy elképzeljük.
És itt jön a képbe a számítógép. Ha ugyanis a számítógépnek megadjuk a feltételezett alapalakokat és szabályokat, akkor ezekből képes legenerálni a ma várt alakokat (ezért hívják generatívnak) – ezeket pedig összevethetjük a valós alakokkal. Ha eltérést tapasztalunk, akkor hiba van a rendszerben. A rendszer működése hasonló a helyesírás-ellenőrzők működéséhez, csak itt a szabályok nem ragozott alakokat hoznak létre, hanem leánynyelvi töveket.
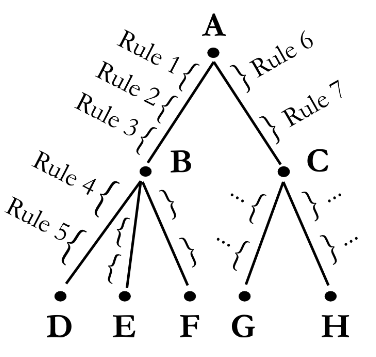
Sajnos a projekt alapján készült teljes szótár még nem érhető el, de némi ízelítőt kaphatunk már belőle. A Helsinki Egyetem honlapján egyelőre egyetlen, ’üt, öl, kovácsol’ jelentésű igető származékait figyelhetjük meg. Az első oszlopban a rekonstruált alakot látjuk, a második oszlopban azt, hogy melyik szó (nyelv és tő) levezetése olvasható, a harmadik oszlopban ennek a szónak a nyelvtani jellemzése és jelentése következik, a negyedik és ötödik oszlopban különböző hivatkozásokat találunk.

(Forrás: Wikimedia Commons / Jorge Royan / CC BY-SA 3.0)
Ha az első oszlopban álló alakra rákattintunk, a szócikk megnyílik, és láthatjuk a teljes levezetést. Az alábbiakban például az orosz кузнец [kuznyec] ’kovács’ szó levezetése látható.

Ebben az esetben az első sor első oszlopában a kiinduló alakot látjuk, a második oszlopban a szabály formalizált alakját, a harmadikban ugyanennek angol nyelvű kifejtését. A negyedik oszlopban a folyamat végeredményét, az ötödikben szakirodalmi hivatkozást. Az új sor első oszlopába már az az alak kerül, amelyet az előző szabály alapján kaptunk (ez állt a negyedik oszlopban), és a folyamat addig tart, míg el nem jutunk a mai alakig (illetve kihalt nyelvek esetében valamelyik ismert, dokumentált alakig).
Az eredmények természetesen vitathatóak, de tény, hogy a módszeresség figyelemre méltó, és előbb-utóbb elvárás lesz a hasonló megoldások használata.