

-
Sándorné Szatmári: @mederi: 11 Kiegészítem a korábbi, mederi néven írt megjegyzésemet.. Ami a cikkben is kife...2025. 06. 05, 13:16 Falánk igék
-
nasspolya: @ganajtúrós bukta: www.reddit.com/r/linguisticshumor/s/BuJhBlK4t82025. 06. 01, 01:06 „Mert nincs rá szó, nincsen rá...
-
Sándorné Szatmári: @szigetva: Korábban számos valóban értelmetlen bejegyzések és viták fóruma is volt helyenk...2025. 05. 18, 16:36 „Mert nincs rá szó, nincsen rá...
-
szigetva: @Sándorné Szatmári: A viták az új cikkek hiánya és a vitaképes kommentelők elmaradása miat...2025. 05. 14, 10:56 „Mert nincs rá szó, nincsen rá...
-
Sándorné Szatmári: @Sándorné Szatmári: 43 Remélem, hogy a 43. hozzászólást már nem törlitek (.. ezt is mentet...2025. 05. 14, 08:39 „Mert nincs rá szó, nincsen rá...
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!


Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság

A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


A nyelvtechnológiában megfigyelhető legújabb törekvési irány a már létrehozott nyelvi erőforrások egységesítése és nemzetközi szabványokhoz való igazítása. Magyarok vezetik azt a projektet, amelynek egyik célja a magyar nyelvfeldolgozó eszközök bekapcsolása az európai ICT véráramába.
A nyelv- és beszédtechnológiáról, annak magyarországi helyzetéről, fejlesztéseiről már többször írtunk. Most egy olyan trendet, törekvést fogunk bemutatni, amely néhány éve erőteljesen megszabja a terület fejlődési irányát. A nyelv- és beszédtechnológiában alkalmazott módszerek és eljárások jellegéből következik, hogy korszerű kutatási eredmények és alkalmazások nem jöhetnek létre a megfelelő nyelvi erőforrások nélkül. Ezek az erőforrások olyan írott és beszélt nyelvi adatbázisok és feldolgozó eszközök, amelyekbe komoly nyelvészeti tudás van beépítve az annotációk segítségével.
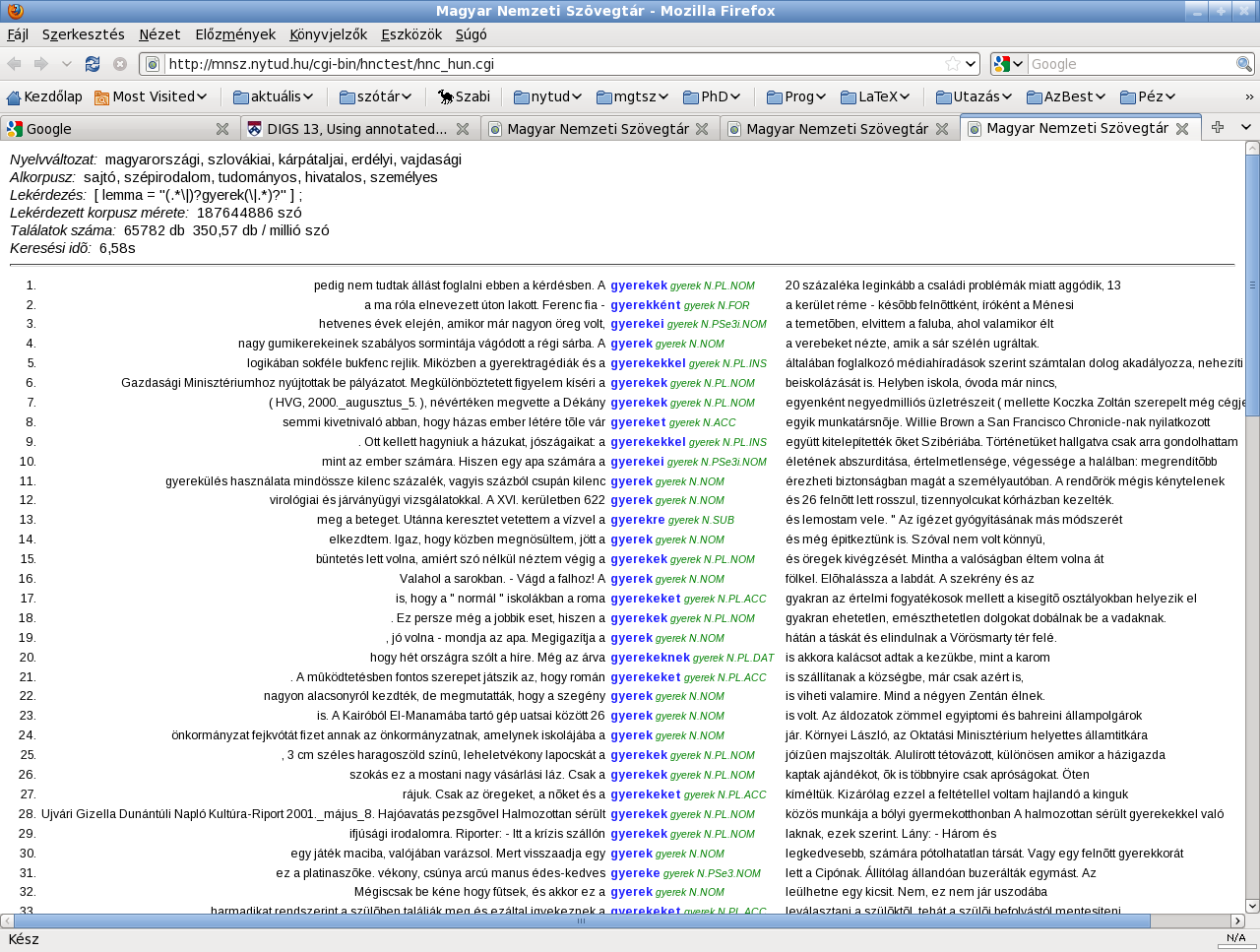
(Forrás: Sass Bálint)
Annotációnak nevezzük azokat a címkéket, amelyek a szöveg vagy beszéd különböző szintű elemeiről szolgáltatnak információt, például a szavakról a szófajukat, a tulajdonnevekről a kategóriájukat, a mondatokról a szerkezetüket mondják meg. Ezek az erőforrások a nyelvtechnológia elengedhetetlen szükségletei a fejlesztésben és az elért eredmények kiértékelésében egyaránt.
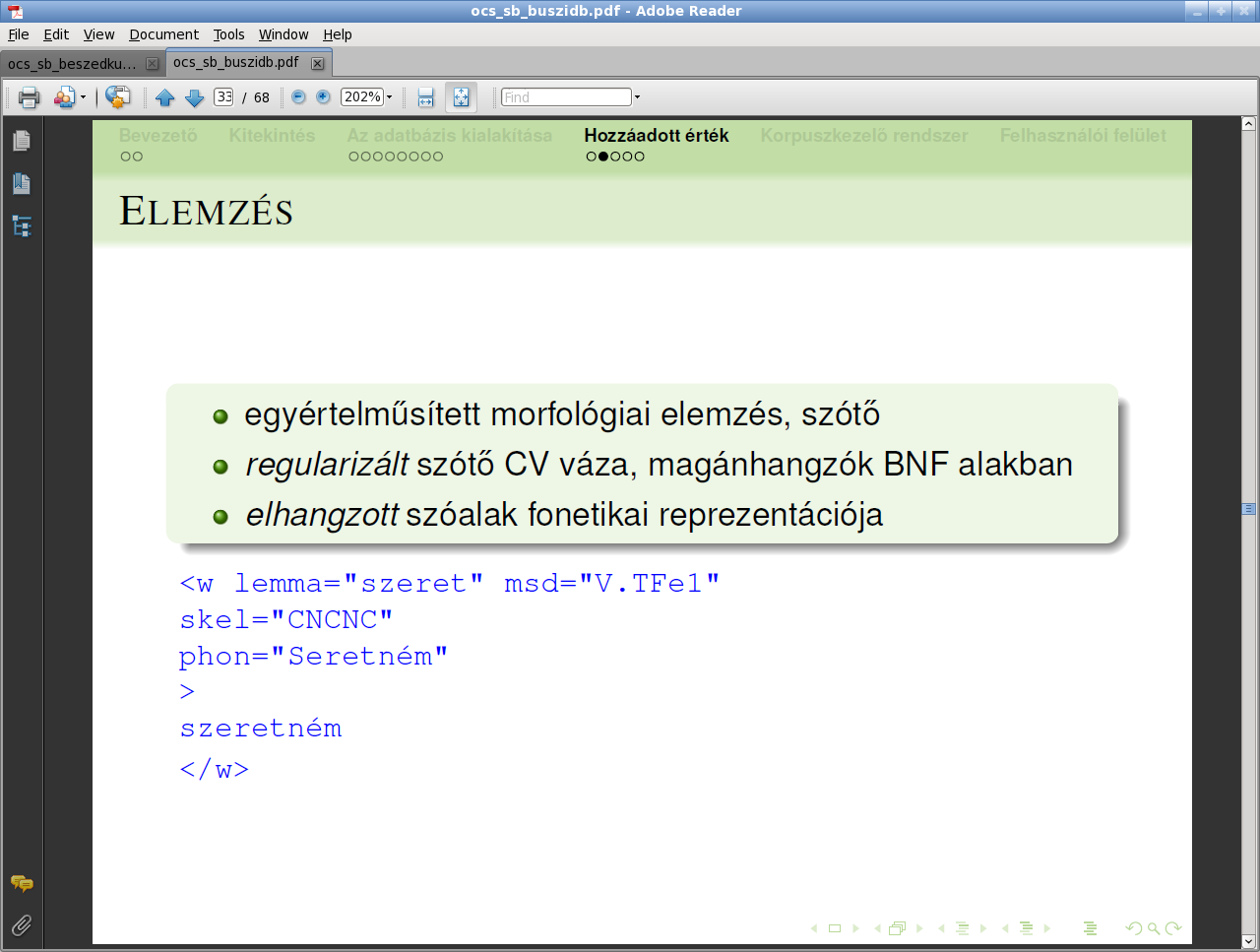
(Forrás: Oravecz Csaba)
Magyar probléma?
A magyar nyelv erősen ragozó jellege miatt a magyar fejlesztők speciális helyzetben vannak, ugyanis a nagyobb európai nyelvekre, elsősorban az angolra kifejlesztett módszerek, eljárások nem feltétlenül adaptálhatók a magyarra. Ezért a magyar nyelvtechnológusok az elmúlt években-évtizedekben saját nyelvi erőforrásokat és nyelvfeldolgozó eszközöket kényszerültek kifejleszteni. Így ma már létezik magyar tokenizáló, mondatra bontó, morfológiai elemző és egyértelműsítő, főnévicsoport-azonosító, tulajdonnév-felismerő, mondatelemző. Viszont mivel a kommunikációáramlás nem mindig megfelelő az egyes kutatóhelyek között, előfordul, hogy ugyanarra a célra szolgáló eszközt több helyen is fejlesztenek. Így egyrészt sok a felesleges átfedés (pl. három különböző magyar nyelvű morfológiai elemző létezik), másrészt az eszközök nem kompatibilisek egymással, ami megakadályozza az összehasonlíthatóságot és a verseny kialakulását.
Az oldal az ajánló után folytatódik...
Ráadásul a már kifejlesztett eszközök közül több a kutatóhelyeken porosodik, sok közülük nincs megfelelően dokumentálva, publikálva, így nem használható. Az eddigi pályázati kiírások új termékek létrehozását célozták, a már meglevők karbantartására, utógondozására, dokumentálására nem fektettek elég hangsúlyt. Viszont a nyelvtechnológia elég dinamikusan fejlődő terület ahhoz, hogy egy pár évvel ezelőtt kifejlesztett eszköz mára már elavultnak számítson. Vagyis az idő előrehaladtával a régebbi eszközök leporolása egyre nagyobb erőfeszítést igényel, ha nem vesznek teljesen kárba. Azért természetesen vannak most is szabadon elérhető, felhasználható eszközök, amelyeket a gazdáik karbantartanak, fejlesztgetnek, de ez meglehetősen sporadikus jelenség. Egy egész ágazatot nem lehet néhány lelkes informatikus önkéntes munkájára alapozni.
Európai probléma!
Szerencsére ez a kutatási-fejlesztési kérdés nem magyar-, sőt még csak nem is K-Európa-specifikus. Ahogy arról már egy tavalyi cikkünkben is beszámoltunk, az EU számára is fontos, hogy újabb és újabb egymástól elszigetelt, nem összeegyeztethető formátumú adatbázisok és nyelvfeldolgozó eszközök létrehozása helyett inkább a már meglevőket szervezze egy egységes infrastruktúrába. Egy ilyen kutatási infrastruktúra kialakításának több sarokköve van: a megfelelő nyelvi erőforrások folyamatos korszerűsítése és fenntartása, a nyelvfeldolgozó eszközök sztenderdizálása, valamint a létrehozott erőforrások terjesztése, és amennyiben lehet, szabadon elérhetővé tétele. Egy ilyen infrastruktúra létrehozása az utóbbi években elsőrendű prioritássá vált, amit egyértelműen jelez az olyan európai projektek elindulása, mint a CLARIN (Common Language Resources and Technology Infrastructure), a FLARENET (Fostering Language Resources Network), a DARIAH (Digital Research Infrastructure for the Arts and Humanities) és az ezt a folyamatot elindító ESFRI (European Strategy Forum on Research Infrastructure).

Ebbe a sorba illeszkedik az idén februárban indult CESAR (CEntral and South-east europeAn Resources) projekt, melynek célja, hogy az ebben a régióban már létrehozott erőforrásokat továbbfejlessze, egységesítse, az európai szabványokhoz igazítsa, és mindenki számára szabadon hozzáférhetővé tegye. A projekt keretén belül magyar, lengyel, horvát, szerb, bolgár és szlovák nyelvű erőforrások előre meghatározott csoportját fogják az adott országok fejlesztői felfrissíteni és a megfelelő metaadatokkal ellátva, szabványosított formában elérhetővé tenni. A közzétételre kiszemelt erőforrások között találunk egy- és többnyelvű írott és beszélt nyelvi adatbázisokat, korpuszokat, szótárakat, valamint különféle szövegfeldolgozó eszközöket (tokenizáló, mondatra bontó, morfológiai és szintaktikai elemző).
A CESAR projekt egy nagyobb európai hálózatnak, a META-NET-nek a része, amelyben 31 ország 44 kutatóközpontja vesz részt, és amelynek célja, hogy a többnyelvű európai információs társadalom technológiai alapjait megteremtse. A CESAR résztvevői szorosan együttműködnek a META-NET-tel, ami elsősorban abban nyilvánul meg, hogy közös szabványokat és módszereket alkalmaznak az erőforrások sztenderdizálásában és újrahasznosításában. A CESAR projekt keretein belül egységesített és interoperábilissá tett erőforrások és eszközök egy közös tárhelyről (META-SHARE repository), vagy a partnerek weboldalain keresztül lesznek elérhetőek.
Magyar és európai
A projektnek azért van kiemelt jelentősége a magyar nyelvtechnológia szempontjából, mert két magyar résztvevője is van: a Budapesti Műszaki és Gazdaságtudományi Egyetem, valamint az MTA Nyelvtudományi Intézete. Ez utóbbi egyben a projekt koordinátora is, a konzorcium vezetője pedig Dr. Váradi Tamás, az intézet nyelvtechnológiai osztályának vezetője. További résztvevők: a Zágrábi Egyetem Bölcsészet- és társadalomtudományi Kara (Horvátország), a Lengyel Tudományos Akadémia Számítástechnikai Kutatóintézete (Lengyelország), a Łodzi Egyetem (Lengyelország), a Belgrádi Egyetem Matematikai Kara (Szerbia), a Mihajlo Pupin Intézet (Szerbia), a Bolgár Nyelvi Intézet (Bulgária) és az Ľudovít Štúr Nyelvi Intézet (Szlovákia).
A projekt két éve alatt a Magyarországon előállított nyelvi erőforrások és nyelvtechnológiai eszközök közül több is be fog kerülni a fent említett tárba, vagyis ezek túl azon, hogy megfelelő dokumentációval és metaadatokkal lesznek ellátva, fel is lesznek újítva. Sőt, néhány közülük ki is lesz bővítve, így előreláthatólag a Magyar Nemzeti Szövegtár mostani méretének többszörösére nő, továbbá a tervek szerint egy kellően nagy méretű, kézzel tulajdonnév-annotált korpusz is készül, amely a későbbiekben a magyar nyelvű automatikus tulajdonnév-felismerő programok tanítására és kiértékelésére lesz használható.
A projekt további hozománya, hogy a META-NET közösség minden résztvevő nyelvéről készül egy ún. white paper, vagyis egy kb. 30 oldalas ismertető az adott nyelv speciális tulajdonságairól, jelenlegi európai helyzetéről, a nyelvtechnológiai kutatások állapotáról, a rendelkezésre álló erőforrásokról és eszközökről, továbbá a kutatási és az ipari szféra kapcsolatáról az infokommunikációs technológiák terén.

Az elkészült bemutatkozó anyagokat az EU nyomtatott formában kiadja, és a június végén, Budapesten megrendezésre kerülő META-Forum 2011 – Solutions for Multilingual Europe című konferencián fogja a nagyközönség elé tárni. A META-Forum a 2011-es magyar EU-elnökség egyik hivatalos eseménye lesz, amelyen részt vesznek az Európai Bizottság és a magyar kormány képviselői, a nyelvtechnológia prominens alakjai, továbbá meghívott előadók a kutatás-fejlesztés és az ipar területéről. A konferenciáról tudósítunk majd, addig is az érdeklődők böngészhetik a rendezvény honlapját.
Forrás
A Nyelv- és Beszédtechnológiai Platform Stratégiai Kutatási Terve és Megvalósítási Terve