

-
Sándorné Szatmári: @CIkk: Mende Balázs Gusztáv kutató csoportja írta "..az avarok anyai ágú etnogenezise egys...2025. 07. 15, 14:43 2. rész: nomád régészeti konferencia...
-
ganajtúrós bukta: Most találtam a wikiben: "Ugyanez a genom 50% manysi (finnugor), 35% szarmata (indoiráni) ...2025. 07. 12, 20:34 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
ganajtúrós bukta: @Sándorné Szatmári: Amúgy nincs kedved kalandmesternek jelentkezni a legközelebbi m.a.g.u....2025. 07. 09, 18:00 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
szigetva: @Sándorné Szatmári: Egyetlen konkrétum van a hosszú szövegedben: a magyarban E3-ban nincs ...2025. 07. 09, 11:17 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @ganajtúrós bukta: Idézet a cikkből: "...erősen kritizálják a nyelvcsalád fogalmát. Ennek ...2025. 07. 09, 10:23 Mi bizonyítja, hogy a magyar nyelv finnugor?
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!


Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság

A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


Hamar munka sosem jó. Az Uralonet, az uráli nyelvek alapnyelvi eredetű szókincsének adatbázisa több mint két évtizeden át készült, habár úgy tűnik, akár három év alatt is megszülethetett volna. Cikkünkben nem csupán a történetét meséljük el, annak is utánajártunk, mire használható mai állapotában.
A tudomány egyik legnagyobb problémája az, hogy azok az adatok, amelyeket felhasználna a kutatáshoz, nem érhetőek el az interneten. Miközben a világban természetessé vált, hogy a minket érdeklő információkat pillanatok alatt megtaláljuk a világhálón, a tudományos munkához szükséges adatoknak, forrásoknak csak kis töredéke férhető hozzá szabadon az interneten keresztül. Pillanatnyilag a legfontosabb feladatok egyike az, hogy a korábban papíron olvasható adatokat, szótárakat, monográfiákat, tanulmányokat elektronikusan is hozzáférhetővé tegyük. Ebben a munkában a magyarországi finnugrisztika most hatalmas lépés megtételével büszkélkedhet.
2012. november 23-án pénteken mutatták be a Magyar Tudományos Akadémia székházában az Uralonetet, az Uralisches Etymologisches Wörterbuch (Uráli etimológiai szótár, rövidítve UEW vagy UEWb) elektronikus változatát. A szótár a hetvenes-nyolcvanas években készült az MTA Nyelvtudományi Intézetének Finnugor osztályán Rédei Károly vezetésével, 1986 és 1989 között jelent meg.
Az oldal az ajánló után folytatódik...
A német nyelvű szótárban címszóként a kikövetkeztetett alapalak szerepel, megadva mellette a kikövetkeztetett alapnyelvi jelentést (szintén németül), azt, hogy melyik (uráli, finnugor, ugor, finn-permi, finn-volgai) alapnyelvre rekonstruálható a szó, illetve biztos vagy csupán lehetséges-e a rekonstrukció. Ezután felsorolják az etimológiához tartozó leánynyelvi megfeleléseket, majd ezt követi a magyarázat. A magyarázatban kitérnek a jelentésváltozásokra és a szabálytalan hangváltozásokra, a leánynyelvi adatokban felbukkanó képzőkre, az esetleges bizonytalanságok okaira stb. A szócikket válogatott bibliográfia zárja, melyben a szó etimológiájára vonatkozó, a szerkesztők által legfontosabb munkák vannak felsorolva.
Luca szájtja
A szótár elektronikus változatának ötlete a nyolcvanas évek végén merült fel Csúcs Sándorban, aki az UEW egyik munkatársa volt. Ő úgy vélte, hogy az UEW bizonyos rekonstrukciói talán nem eléggé következetesek, de ennek ellenőrzéséhez rengeteg adatot kell előkeresni, amely a szótárral vagy cédulákat használva szinte megoldhatatlan (de legalábbis rengeteg időt követelő) feladat. A számítógép segítségével viszont másodpercek alatt megtalálhatjuk a minket érdeklő adatokat.
Ma már persze érezhetjük úgy, hogy az ötlet kézenfekvő volt, de annak idején forradalminak volt mondható. Ebben az időben csupán néhány számítógép volt a Nyelvtudományi Intézetben, a kutatók még kézzel írták cikkeiket, amelyeket gépírónők gépeltek le, és az így készült kéziratok mentek a nyomdákba. Akkoriban úgy képzelték, hogy majd lesz a sarokban egy számítógép, amelyre telepítve lesz az UEW elektronikus változata, és azok a kutatók, akik a szótár anyagával szeretnének dolgozni, majd e gép mellé fognak ülni, elvégzik a kereséseket, majd átadják helyüket másoknak. Később, a CD-technológia elterjedésével már úgy képzelték, hogy a szótár anyaga forgalmazható lesz, és akár a külföldi kutatóhelyeken, vagy otthon is használhatják az érdeklődők. Az internet elterjedésével (illetve a CD-technológia elavulásával) persze már egy online hozzáférhető, folyamatosan frissíthető, javítható, bővíthető változatot tartottak már szem előtt.
A szótár elektronikus változatának munkálatait 1991-től 2009-ig, nyugdíjba vonulásáig Csúcs Sándor vezette. A szótár anyagát már a kilencvenes években első felében rögzítették a Finnugor osztály munkatársai, méghozzá egyszerűen úgy, hogy az anyagot Microsoft Wordbe írták, RTF-formátumban mentették. A kellő számítógépes tudás azonban ekkor nem volt meg az intézetben, éppen ezért a munkálatokba bevonták Bátori Istvánt, aki ekkor a Koblenz Egyetemen a számítógépes nyelvészeti intézetet vezette, korábban pedig maga is finnugrisztikával foglalkozott. Ettől kezdve a technikai fejlesztést Bátori vezette, a szoftver fejlesztésébe több tanítványát, szakdolgozóját is bevonta. A szoftver jelentős része el is készült, a funkciói többé-kevésbé működtek, ám meglehetősen megbízhatatlanul: valódi munkaeszközként nem volt használható.
Eközben Csúcs Sándor szorgalmasan bővítgette az adatbázist: a szócikkeket kiegészíttette más rekonstrukciókkal (például Collinderéivel, Janhunenéivel), a leánynyelvi adatokat az időközben megjelent szótárakéival (például az udmurt adatokat Wichmann udmurt szótárának adataival), megadta a rekonstruált jelentéseket angolul és magyarul is, illetve beledolgozta az anyagba saját permi rekonstrukcióit.
A projekt eredetileg Uráli Etimológiai Adatbázis (UEA), majd UEDb (Uralische Etymologische Datenbasis, Uráli Etimológiai Adatbázis) néven futott. Később a Bátori-féle változat az Uralothek nevet kapta, a Nyelvtudományi Intézetben fejlesztett változatot pedig az Uralonetnek nevezték el. Az UEDb név előnye volt, hogy erősen emlékeztetett az alapjául vett szótár címének rövidítésére (UEWb). Az új elnevezéseket semmiképpen nem tarthatjuk szerencsésnek, hiszen nem utalnak arra, hogy etimológiai szótárról van szó: éppúgy lehetne uráli nyelvészeti tanulmányokat, uráli nyelvű szövegek internetes gyűjteményét (korpuszát) stb. így nevezni. Az Uralonet logója már sokkal szerencsésebb, szellemes választás.
2009-ben Csúcs Sándor nyugdíjba vonult, a szoftver viszont továbbra sem volt publikálható állapotban. A Finnugor és nyelvtörténeti osztály munkatársai úgy döntöttek, hogy a szótár kiadása nem halogatható tovább. Az intézet nyelvtechnológiai osztályát kérték fel arra, hogy segítsenek rendbe hozni a Bátori-féle verziót, ám az ottani munkatársak úgy látták, célszerűbb az adatbázisban való kereséshez egy újabb programot fejleszteni, mint Bátori verzióját javítgatni. Ebben az időben Bátori István is publikálta a maga adatbázis-kezelőjének tesztváltozatát: ez ma is elérhető az interneten. (Ezt a változatot linkeli az Uralonet is, ámde rosszul: az ott megadott címen ma már nem érhető el a szolgáltatás.)

A szoftver fejlesztésével párhuzamosan elindult az adatbázis ellenőrzése, és ennek során kiderült, hogy ebben is rengeteg hiba van. Végül a nyolcvanmillió karaktert tartalmazó adatbázist olyan mélységig kellett ellenőrizni, hogy az gyakorlatilag felért az újrarögzítéssel. Ráadásul a legtöbb Csúcs-féle bővítés nem volt meg benne: az anyag kizárólag a jelentések angol és magyar megadását, illetve Csúcs permi rekonstrukcióit tartalmazta. Az előbbieket alapos ellenőrzés és javítás után meghagyták, az utóbbiakat viszont – legalábbis ideiglenesen – jobbnak látták eltávolítani az adatbázisból.
Érdekes módon az Uralonetet már többször bemutatták, legelőször szinte napra pontosan két évvel a mostani bemutató előtt, 2010. november 22-én *kala a hálón címmel a Nyelvtudományi Intézetben. A következő két év folyamán több ilyen bemutató is volt, ám az oldalon ott virított a „Még nem végleges változat” felirat, mely idén november végén végre eltűnt. Az első igazi változatnak tehát a mostani tekinthető.
Az új szoftver és adatbázis már megfelel rengeteg olyan követelménynek, amelynek a Bátori-féle változat nem felelt meg. Bátori saját karakterkészletet használt, és az adatokat is sajátosan kódolta (például a diftongusokat egy számmal kódolta, azaz pl. az uo betűkapcsolatot egyetlen kód, és nem kettő – az u-é és az o-é) jelölte. Ennek hatalmas hátránya, hogy az interneten az adatbázis adatai csakis az erre készült adatbázis-kezelővel kereshetőek, a Google vagy a hasonló netes keresők nem fogják megtalálni az adatokat. (Ne felejtsük el, hogy a Bátori-féle változat kidolgozásának kezdetekor az internetes megjelenés még fel sem merülhetett!) Az Uralonet ezzel szemben a Unicode-kiosztást használja és a jelenlegi szabványok szerint kódolja az adatokat, így a netes keresőkkel is elérhető. További előnye, hogy a megjelenített adatok így könnyen másolhatóak, beilleszthetőek szövegszerkesztőkbe, mailbe stb., azaz sokkal könnyebb dolgozni velük.
A fejlesztők néhány új, hasznos funkciót is bevezettek. Így például a magyar adatok mellett megjelentek a MNSz, illetve a HHC feliratok, melyekre kattintva a Magyar Nemzeti Szövegtárban, illetve a Magyar Történeti Korpuszban kereshetjük ki az adott szót. (Arra persze ügyelni kell, hogy nem minden találat tartalmazza ugyanazt a szót!)
Összességében tehát elmondhatjuk, hogy hatalmas jelentőségű munkáról van szó: a világon először érhető el egy teljes nyelvcsalád etimológiai szótára internetes adatbázisként. Ha hozzátesszük, hogy az adatbázis-kezelőt újonnan kellett kifejleszteni, az adatbázis ellenőrzése pedig szinte felért annak újbóli rögzítésével, akkor könnyen beláthatjuk, hogy hatalmas munkáról volt szó. A magyar tudományosság ismét jelentős eredménnyel büszkélkedhet.
Lássuk a medvét halat!
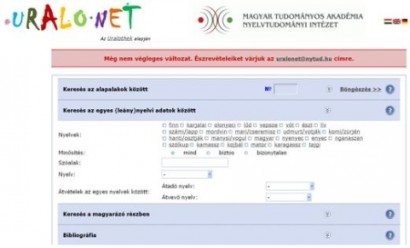
Az Uralonet nyitóoldaláról a többfelé juthatunk, így például megnyithatjuk az oldalra vonatkozó információkat, a súgót, illetve az oktatáshoz nyújtott segédanyagokat. Az Uralonet érdemi része azonban a Keresőfelület menüpont alatt található, tulajdonképpen ezt nevezhetjük az Uralonetnek. A magunk részéről célszerűbbnek tartanánk, ha a keresőfelület lenne a nyitóoldal, hiszen a súgó megnyitására itt is lehetőség van, a többi részhez mindössze két linket kellene itt elhelyezni.

A keresőfelület négy fiókra oszlik, és különböző adattípusokra kereshetünk rá. A felső fiókban a rekonstruált szavakra kereshetünk, a másodikban a leánynyelvek adataira, a harmadikban a magyarázó részekre, a negyedikben pedig a bibliográfiai adatokra.
Az alapalakokra való keresés fiókjában legfölül azt állíthatjuk be, hogy hol kereshetjük az adatokat: meghatározhatjuk, hogy melyik rekonstruált alapnyelvben szeretnénk kutatni, illetve hogy a biztos vagy a bizonytalan rekonstrukciók érdekelnek-e minket (vagy mindkettő). Sajnos vagy csak az egyik alapnyelvet választhatjuk, vagy az összeset, holott lehet, hogy az alapnyelvek egy csoportja érdekel minket. Például ha az olyan etimonok között keresgélnénk, melyek a magyar számára relevánsak (tehát az uráli, a finnugor, vagy az ugor nyelvre rekonstruálták őket – a finn-volgai és a finn-permi adatok ekkor nem érdekesek), de a magyarban nem feltétlenül van megfelelőjük, akkor a három alapnyelvre külön kell rákeresnünk. De az is lehet, hogy olyan etimonokat keresünk, melyeket a finn-permi és az ugor nyelvekre rekonstruáltak, de a finnugorra vagy az urálira nem, és éppen az érdekel minket, hogy ezeket nem lehetne-e mégis összekapcsolni valahogy, a program akkor sem segít nekünk, egy csomó munkát kézzel kell elvégeznünk – pedig programozásilag nem lenne nagy ügy megoldani, hogy tetszőleges alapnyelvi kombinációkban kereshessünk.
A fiók következő két mezőjében megadhatjuk, hogy mit keressünk. A felsőben azt, hogy milyen fonémasorokra (betűsorokra) kereshetünk rá: megadhatjuk, hogy ezeket a program a szavak elején, közepén vagy végén keresse-e, vagy teljes szavakra keressen rá. Az alsóban pedig fogalomkörök alapján szűkíthetjük a jelentést, illetve adott jelentésű rekonstrukciókat kereshetünk!
A tesztek a 2012. november 27-ei állapotokat tükrözik.
Elvégeztünk egy egyszerű próbát! Rákerestünk az š kezdetű szavakra: a megfelelő karakter a magyar billentyűzetről könnyen elérhető az AltGr+2 s billentyűkombinációval, de a képernyőn látható megfelelő gombra kattintva is beírható – a szoftver tehát itt előzékenyen segíti a felhasználót. Azt az eredményt kaptuk, hogy ilyen szó nincs – ez meglepheti azokat, akik valaha tanultak uráli hangtörténetet! Tettünk egy próbát a ś-sel (ez az AltGr+9 s billentyűkombinációval is elérhető): az eredmény hasonló. Az egyszerűség kedvéért rákerestünk rá az s kezdetű szavakra: a dolog működött, sőt, túlontúl jól is működik: ezúttal ugyanis kilistázásra kerülnek az ś és š kezdetű szavak is! Ha jobban megfigyeljük, kiderül a hiba forrása is: ezek a szavak nem az ś, illetve š karakterekkel, hanem az s + ́, illetve s + ̌ karakterekkel van kódolva. (Megfigyelésünk szerint a probléma minden mellékjeles betűnél fennáll.) Később más számítógépen is elvégeztük a teszteket, és ott az ékezetes keresés működött: elképzelhető, hogy a fejlesztők is ilyen gépen dolgoztak, ezért nem fedezték fel ezt a hibát. Ugyanakkor az mellékjel nélküli karakterekkel keresve minden esetben megkapjuk a mellékjeles karakteres találatokat is – ráadásul a lista elején, így ezt a hibát viszonylag könnyű kiszűrni.

(Forrás: Wikimedia Commons / INVERTED)
Szintén kellemetlen, hogy például a δ̕ begépelését semmi nem segíti, mivel önálló gombja nincs. Így először a δ-t kell a gmb segítségével beírni, majd az AltGr+9 szóköz billentyűkombinációval kell begépelni a mellékjelet.
Ennek oka bizonyára az, hogy bizonyos hasonló karaktereknek nincs Unicode-kódjuk, így például a δ̕ másképp nem is kódolható. Az egységesség tehát indokolja ezt a megoldást. Az azonban aligha érthető, hogy ha az adatok így vannak kódolva, akkor az adatbázis-kezelő miért nem így keresi őket. További probléma, hogy a netes keresőket használva bizonyára senki nem fogja a s + ́, illetve s + ̌ kombinációkat használni, így Unicode ide, Unicode oda, az adatok nem érhetőek el az adatbázis-kezelőn kívül. (A jelenlegi állapotban – legalábbis egyes számítógépeken – a saját adatbázis-kezelővel sem.) A javítás során mindenképpen inkább a kódolást kellene megváltoztatni, hiszen ellenkező esetben ügyelni kell, hogy a mellékjel nélküli betűkre keresve a kereső ne dobja ki a mellékjeles betűket is – ez pedig ha nem is megoldhatatlan, de bonyolultabbá teszi a keresést.
Ha sikerül adatokat elővarázsolnunk az adatbázisból, akkor az az első ötven találatot listázza, jelezve a találatok számát. Elvben a további adatok listázására is mód lenne, de a megfelelő linkekre kattintva új keresés indul. Ugyanez a helyzet, ha megpróbálunk egyszerre tíz vagy száz adatot listázni – a funkciók nem működnek. Ennek köszönhetően az összes releváns adat nem is érhető el.
A rekonstruált alakok szótagszerkezetére is kereshetünk, ha a mássalhangzók helyére C-t, a magánhangzók helyére V-t írunk. Ezeket valódi hangokkal is pótolhatjuk, például ha a CaCCa keresőkifejezést használjuk, akkor megkapjuk azokat a rekonstruált alakokat, melyek két szótagúak, mindkét magánhangzójuk a, mássalhangzóval kezdődnek és a szótaghatáron két mássalhangzó áll.
A második fiókban a leánynyelvi adatokra kereshetnénk rá. Valójában sajnos nem tehetjük, csupán azt adhatjuk meg, hogy milyen nyelvben előforduló adatok érdekelnek minket. Rákereshetünk tehát például olyan etimonokra, amelyeknek magyar megfelelőjük van. Sajnos azonban nem kereshetünk olyan etimonokat, amelyeknek adott nyelvekben nincs megfelelőjük – például olyanokra, amelyeknek van finn, de nincs észt folytatójuk, vagy van obi-ugor, de nincs magyar folytatójuk. Az előbbi megoldható lenne azzal, ha amellett, hogy milyen leánynyelvben van megfelelő, azt is beállíthatnánk, hogy melyben ne legyen. Az utóbbi már bonyolultabb lenne, hiszen logikai viszonyokat kellene felállítani: legyen manysi VAGY hanti megfelelő (de nem szükséges mindkettő), de ne legyen magyar. Ez valóban komolyabb fejlesztést igényelne, de hosszabb távon ez is elengedhetetlennek látszik, ha valóban jól használható eszközt szeretnénk.

A másik lehetőség, hogy a leánynyelvek között kölcsönzött, de alapnyelvi eredetű szavak között keresünk. Például ha átadó nyelvként beállítjuk az észtet, átvevőként pedig a finnt, akkor megtudjuk, hogy három olyan ősi szó van, melyet a finn ugyan nem őrzött meg, mégis megtalálható benne észt jövevényszóként. (Ellenkező irányban 21 kölcsönzés történt: ebből azonban nem érdemes messzemenő következtetéseket levonni, hiszen itt nem az összes, az észt és a finn között végbement kölcsönzésről van szó, csak az alapnyelvi eredetű szavakról.) Az átadó és átvevő nyelvek között csak az uráli nyelvek egy része jelenik meg, más részük (így a magyar) nem: feltehetően azért, mert ezek sem átadó, sem átvevő nyelvként nem szerepelnek. Ez a funkció jól látszik működni, bár a vaktesztelés itt is érdekes eredményt hozott. Amikor rákerestünk, hogy hány lív szó került át más nyelvbe, kiderült, hogy csak egy: a *kewe ’állat nősténye’, méghozzá melyik nyelvbe? Olvasóink nem fogják kitalálni: a lívbe. Feltehetően adatrögzítési hibáról van szó, melyet nehéz észrevenni, de ha nekünk ilyen gyorsan sikerült egy ilyen hibába belerohannunk, joggal tehetjük fel a kérdést, hogy hány hasonló hiba lehet még. (Az önkölcsönzés ilyen esetei az adatbázisból könnyen kiszűrhetőek, ámde felmerül a kérdés, mi van, ha a kölcsönző nyelv rosszul van jelölve, ám nem azonos a kölcsönzővel...)
A különböző fiókok közötti kereséseket lehet kombinálni,tehát rákereshetünk olyan szavakra, tehát például rákereshetünk olyan szavakra, melyek az alapnyelvben p-vel kezdődtek, van finn és magyar megfelelőjük, és a komiból valamely más uráli nyelv átvette őket. Két ilyen szót találunk, a magyar facsar és a fúr megfelelőit.
A legnagyobb hiányosság, hogy leánynyelvi adatokra közvetlenül nem lehet keresni. Ez különösen azért furcsa, mert a korábbi változatban ez még lehetséges volt. Feltehető, hogy nem csupán az egyszerű felhasználók, de a szakemberek is leggyakrabban egy-egy mai szó etimológiájára lesznek kíváncsiak. Tegyük fel, hogy a magyar nyelv szó eredetére vagyunk kíváncsiak. A legegyszerűbb lenne, ha beírnánk a keresőbe, hogy „nyelv”, és az megtalálná a megfelelő szócikket – ahogy erre korábban lehetőség volt.A jelenlegi változatban azonban ezt nem tehetjük meg, hiszen közvetlenül csak az alapnyelvi alakokra kereshetünk, azt pedig a szakértők is csak ritkán tudják biztosan fejből, az érdeklődő laikusnak pedig fogalma sem lehet róla. Maradna tehát az a fapados megoldás, hogy kilistázzuk az összes magyar szót (ezt a nyelv elnevezésére
(Forrás: anyanyelv-pedagogia.hu)
kattintva tehetjük meg): az első oldalon meg is jelennek a magyar szavak az ad-tól az ëgyházig, és a program jelzi, hogy az adatok még hat további oldalon folytatódnak. Tippünk szerint a nyelvnek valahol a 3. vagy a 4. oldalon kell lennie – a számokra kattintva azonban nem a magyar, hanem az alapnyelvi adatok listázása folytatódik!
Próbálkozhatunk azzal a trükkel, hogy az alapnyelvi jelentéshez írjuk be a nyelvet: ebben az esetben kapunk is két találatot, melyek közül az egyikben valóban ott lesz a magyar nyelv. Ez a módszer azonban nem működik minden esetben. Ha például az ’ajtó’ jelentésre keresünk rá, megint két találatot kapunk, de ezek közül egyik sem lesz magyar adat. Ebből azonban elhamarkodott lenne azt a következtetést levonni, hogy a magyar ajtó nem alapnyelvi eredetű! Az ajtó az ábécé elején áll, így szerepel a magyar adatok első oldalán: kideríthető, hogy egy ugor ’eloldódik, kiszabadul’ jelentésű ige származéka.
Hasonló keresésekre nem csupán a kutatónak lehet szüksége. Például az is elképzelhető, hogy egy középiskolai tanár szeretné kigyűjteni az olyan magyar szavakat, amelyek f-fel kezdődnek, de van finn megfelelőjük is. Jelenleg erre nincs módja, de ha a magyar adatok listázása működne, akkor is csak azt tehetné, hogy az összes szócikket, amelyben f-kezdetű magyar adat szerepel, megnyitja, és megnézi, melyikben van finn adat. Az igazi megoldás persze az lenne, ha lehetne egyenesen olyan listát készíteni, amelyekben csak a finn és csak a magyar adatok szerepelnek (ha egyszer csak ezekre van szükségünk), és nem kellene kézzel kopipésztelni a szükséges adatokat. Ettől azonban még fényévekre van a rendszer.
A valódi kutatási feladatokhoz azonban ez sem volna elég. A Csúcs-féle eredeti ötlet ennél összetettebb kereséseket igényelne. Például tudjuk, hogy a hal szó finn megfelelője kala, és az alapnyelvi alakot is így rekonstruáljuk: *kala. De vajon következetesen a-t rekonstruálunk az első szótagban, ha a magyarban és a finnben is a áll ott? Ezt úgy tudnánk ellenőrizni, ha tudnánk olyan alakokra keresni, melyeknek van finn és magyar folytatójuk is, és mindkettő első szótagjában a áll. Az adatbázis birtokában ez könnyű feladat lenne, ámde a kereső ilyenre lehetőséget sem kínál – holott valójában éppen ez az, amire érdemes lenne használni. A rekonstruált alakok sokkal kevésbé érdekesek, hiszen ezek feltételezéseken alapulnak, nem tények. Egy eljövendő kutatás sokkal inkább arra irányulhat, hogy ezeket felülbírálja, módosítsa: ehhez azonban a leánynyelvi adatok, és nem a rekonstrukciók között kellene keresgélni!
A harmadik fiókban a magyarázó részekben lehet keresni – mivel ezek német nyelvűek, természetesen németül. Először a „tschuw.” betűsorra próbáltunk rákeresni, feltételezve, hogy ez a csuvas nyelv rövidítése, és mivel a csuvas több finnugor nyelvvel is érintkezett, feltehetően valahol említik. Sajnos feltételezésünk megalapozatlannak bizonyult, mert találatot nem kaptunk. Ezutána a „tat.” rövidítéssel próbálkoztunk, hátha a tatár nyelvet említik. Ekkor két találatot kaptunk: az egyik esetben nem a tatárról volt szó:
s. noch unter *meke 'Sache, Tat...; tun, machen, arbeiten'
Ebben az esetben a német Tat ’tett, cselekedet’ szó bukkant fel, de a keresés természetesen sikeresnek tekinthető. A másik esetben valóban a tatárra történt utalás:
Die Herleitung von ung. szösz aus einer Turksprache: kas.-tat. süs 'Werg, Hede', tschuw. süs 'zum Spinnen bereiteter Hanf od. Flachs' (Munkácsi: NyK 21: 127; Gombocz: MNy. 3: 358), ist nicht akzeptabel. Kas.-tat. süs ist möglicherweise ein syrj. Lehnwort, das tschuw. Wort stammt aus dem Kas.-Tat.
Ebben az esetben valóban tatár adatokat találunk – ami igazán megdöbbentő, az az, hogy csuvasokat is, méghozzá éppen a várt „tschuw.” rövidítéssel! A hibát sem nehéz megtalálni: a rövidítést záró pont ugyanis már nem félkövéren van szedve, a félkövér szedést záró html-tag pedig a karaktersorba ékelődik. Az már eleve hiba, hogy a pont hol félkövéren van szedve, hol nem, így a rögzítés eleve következetlen. Az azonban egyenesen érthetetlen, hogy a keresés miért nem ignorálja a beékelődő html-tageket. Persze az elegáns, adatbázishoz méltó megoldás az lenne, ha eleve lehetne nyelvek alapján keresni a megjegyzésekben, de erre feltehetően még néhány évtizedet várnunk kell.

Biztató viszont, hogy a negyedik fiókban a bibliográfiai adatok között már hasonló módon kereshetünk. Itt ugyanis azt adhatjuk meg, hogy mely szerzőkre, vagy mely művekre (monográfiákra, folyóiratokra stb.) való hivatkozásokat szeretnénk megtalálni. Sajnálatos (és némiképpen érthetetlen) módon a kettőt nem tudjuk kombinálni, tehát nem tudunk rákeresni például Munkácsi Bernátnak a Nyelvtudományi Közleményekben megjelent írásaira való hivatkozásokat. Bizonyára nem gyakoriak az olyan tudománytörténeti kutatások, ahol pont ilyesmire lenne szükség, de ha egyszer a lehetőség meglenne rá, nem világos, miért kell tiltani.
Az már kevésbé érthető, hogy miért kell külön szerzőként feltüntetni Radanovicsot, Radanovics (Rédei)-t, pláne Rédei (Radanovics)-ot, illetve Lytkint és Lytkint! Az előbbire (vagy az utóbbira?) például csak egyszer történik hivatkozás, a másikra viszont 424 szócikkben! Megint azzal az esettel állunk szemben, amikor a hiba kiszűrése minimális erőfeszítést igényelt volna: ha valaki csak megnyitja a szerzők listáját, azonnal feltűnik, hogy Lytkin és Rédei (Radanovics) neve a névsoron kívül, annak elején áll – még csak nem is a végére van elrejtve!
Patyomkin-szindróma
Összességében meg kell állapítanunk, hogy az Uralonet jelenlegi állapotában nem több egy Patyomkin-falunál: látszólag egy csodálatos adatbázis, mely valójában használhatatlan: az első „működő”, „kész” verzió a legalapvetőbb funkciók ellátására is alkalmatlan. Ami azért is különösen szomorú, mert nem egyszerű kamuról van szó, hanem hatalmas munka áll mögötte. Szerencsére elmondhatjuk, hogy ez a falu könnyen lakhatóvá tehető, ha kijavítják a legalapvetőbb hibákat. Mi több, némi fejlesztéssel az is elérhető, hogy jól élhető, nyüzsgő várossá fejlődjön.
Az egyetlen ok, ami pesszimistává tehet minket, az adatbázis története. Úgy tűnik, hogy az utóbbi két-három évben sem változott a projekt történetét jellemző két évtizedes tendencia, mely szerint a fejlesztés során csupán egyetlen szempont nem érvényesül: hogy a program valóban működjön, használható legyen. Nem látjuk, mi arra a garancia, hogy a következő két hétben, két hónapban vagy akár két évben ez megváltozzon. Nem értjük, hogy az ország egyik vezető nyelvtechnológiai műhelyében hogy feledkezhetnek meg arról, hogy a szoftverfejlesztés egyik legfontosabb része az alapos tesztelés. Nem értjük, hogy a fejlesztésben részt vevő finnugrista szakemberek hogy tudnak kiállni a nyilvánosság elé azzal, hogy a mű elkészült, anélkül, hogy a legalapvetőbb tevékenységeket, amelyeket a várható felhasználók elvégeznének, nem végzik el, és nem ellenőrzik, hogy a program valóban működik-e.
A magunk részéről természetesen annak örülnénk a legjobban, ha nemsokára valóban használható lenne a program, hiszen etimológiai cikkeink megírásához eddig is használtuk, amikor lehetett. A fentiek ismeretében azonban bizonyára érthető a szkepticizmusunk.